4월 2주차 Weekly Report
Table of contents
주간 작업 내용
4월 2주차 작업내용이다. 팀원별 업무 내용은 다음과 같다.
박종현, 이제욱 : PPG 시그널 전처리 및 필터링 기술 서베이 및 심박수 시그널의 보간 코드 분석 진행 이태우 : 수면단계 모델 학습 및 성능평가
-
04.08(화) 17:30 ~ 21:00 : PPG 시그널 전처리 및 필터링 기술 서베이 / 학습을 진행할 모델 선택
-
04.10(목) 16:00 ~ 18:00 : PPG 시그널 전처리 및 필터링 기술 서베이 및 코드 분석 / 수면단계 특징 추출
-
04.13(토) 15:00 ~ 23:00 : 학습을 진행할 모델 선택 / 모델 튜닝
LSTM 모델을 사용한 시퀀스 데이터 학습
데이터 전처리 및 카테고리화
지난 주에는 간단한 classifier를 사용하는 것은 정확도가 매우 낮다는 결과가 있었다. 이번 주에는 딥러닝을 이용한 LSTM 모델을 도입하여 학습을 진행할 예정이다.
데이터셋의 파일이름은 다음과 같다.
46343_cosine_feature.out
46343_hr_feature.out
46343_psg_labels.out
...
여기서 4가지 카테고리로 나눌 수 있음.
cosine_featureshr_featurestime_featurespsg_labels
4가지 카테고리로 하나에 큰 벡터 4개로 만들고 이를 학습데이터로 이용하려고 한다. 여기서 cosine_features, hr_features, time_features는 모델의 입력값으로 사용되었고, psg_labels는 목표 변수(y값)로 사용되었다. psg_labels는 0부터 5까지의 값을 가지며, one - hot encoding을 통해 카테고리화를 진행하였다. 이 설정은 모델이 더 정확하게 클래스를 분류하도록 한다.
모델 구조
LSTM 모델을 생성할 때, 다음의 구조를 따른다:
- 입력 레이어: 이 레이어는
cosine_features,hr_features,time_features로부터 input으로 받는다. - LSTM 레이어: 시계열 데이터의 기억을 보존하며 학습하기 위해 LSTM 레이어를 사용하였다.
- 출력 레이어: 클래스 분류를 위해
softmax활성화 함수를 사용하는 Dense layer를 추가하였다. 이 레이어는 각 클래스에 속할 확률을 출력한다.
모델은 0~5 라벨 값에 확률을 나태내므로 라벨값을 0~5 값의 one - hot encoding으로 변환 후 크로스 엔트로피 손실 함수(cross entropy)를 사용하여 학습하였다.
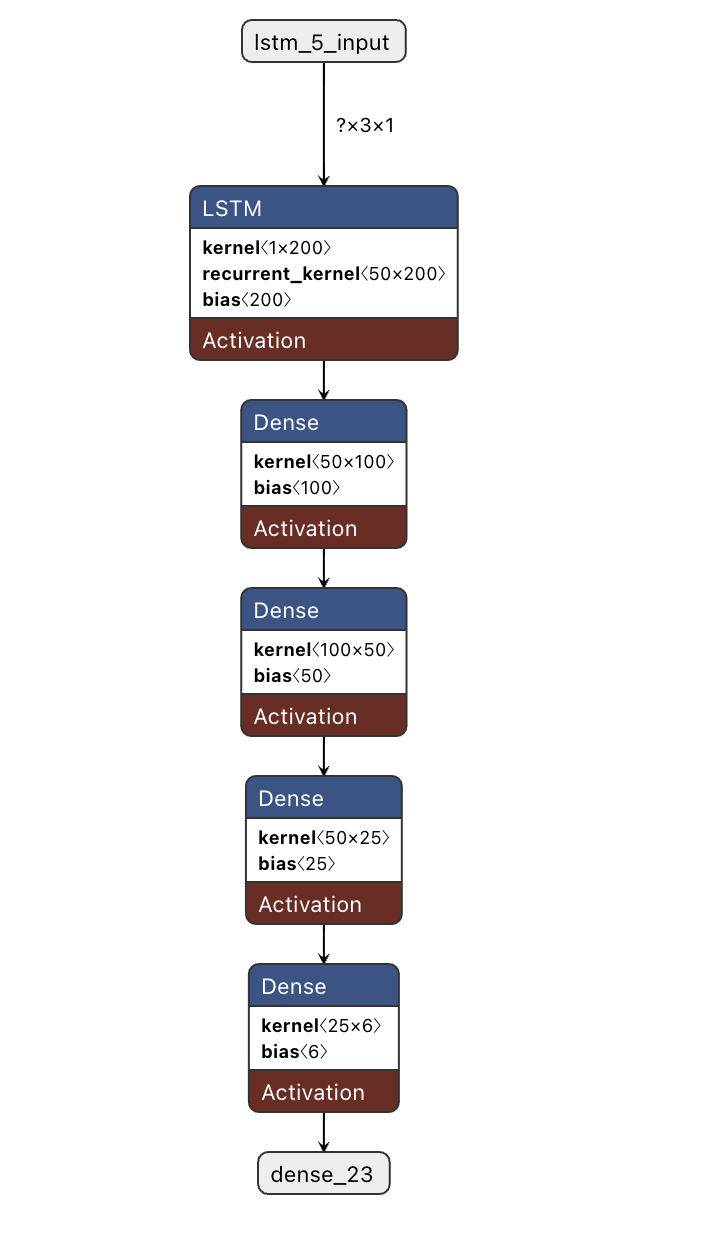
LSTM Model
위 모델은 colab의 TPU v2환경에서 진행하였다.
- model.py
import numpy as np
import os
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
def load_feature_data(base_path, feature_pattern):
all_data = []
for filename in os.listdir(base_path):
if feature_pattern in filename:
file_path = os.path.join(base_path, filename)
try:
# Load all data from file
data = np.loadtxt(file_path)
if data.ndim == 1: # Ensure data is two-dimensional
data = data.reshape(-1, 1)
all_data.append(data)
except Exception as e:
print(f"Error reading {file_path}: {e}")
if all_data:
return np.concatenate(all_data, axis=0)
return np.array([]) # Return an empty array if no data
# Set file path
base_path = '/content/drive/MyDrive/features'
# Load all feature data
cosine_features = load_feature_data(base_path, 'cosine_feature')
hr_features = load_feature_data(base_path, 'hr_feature')
time_features = load_feature_data(base_path, 'time_feature')
psg_labels = load_feature_data(base_path, 'psg_labels') # Assuming this is the label data
y_one_hot = to_categorical(psg_labels, num_classes=6)
# Combine features into one array (adjust as necessary)
features = np.stack([cosine_features, hr_features, time_features], axis=1)
print(features.shape)
print(psg_labels.shape)
# Reshape data to include time step dimension for LSTM
X = features.reshape(features.shape[0], features.shape[1], 1) # Adding time dimension
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y_one_hot, test_size=0.2, random_state=42)
# Construct the model
model = Sequential([
LSTM(50, activation='tanh', recurrent_activation='sigmoid', input_shape=(X_train.shape[1], X_train.shape[2]), dropout=0, recurrent_dropout=0),
Dense(100, activation='relu'),
Dense(50, activation='relu'),
Dense(25, activation='relu'),
Dense(6, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=3000, validation_split=0.2)
model.save('my_model.h5')
loss, accuracy = model.evaluate(X_test, y_test)
print(f"Test Accuracy: {accuracy*100:.2f}%")
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend()
plt.show()
모델을 설계하기에 앞서서 먼저 lstm 단일 layer와 y값에 대한 layer로 2-layer에 대한 모델을 먼저 구현해 보았다. 구현 결과 lstm layer와 fcn layer 2개를 이어 붙인 모델보다 정확도가 많이 떨어졌으며 loss값이 많이 줄어들지 않았다. 
epoch를 3000번 해 보았는데 그래프를 보면 에포크 1000번에서 멈추는 것이 overfitting을 줄이기에 좋은 epoch이다. 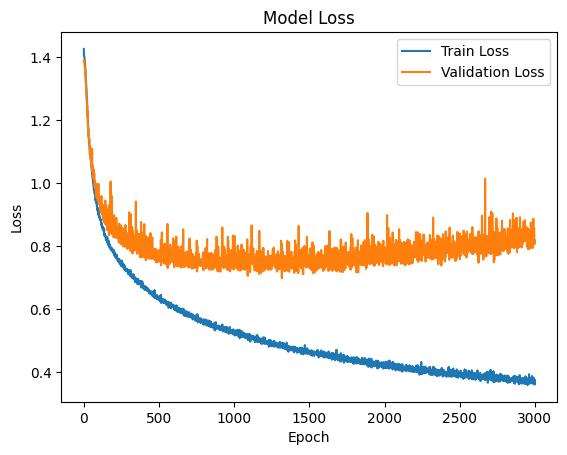
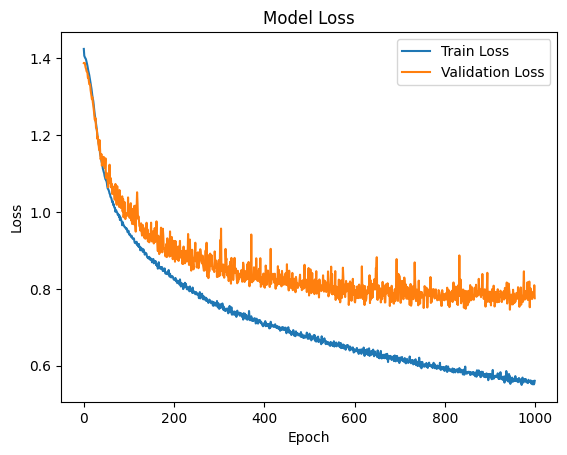
에포크를 1000번으로 줄여서 overfitting을 방지하였다.
정확도는 78% 정도로 비교적 정확하다. 우리가 하려는 것은 수면 단계를 정확히 파악하는 것이 아닌 사용자가 잠을 잘 자는지 추론하는 것이기 때문이다.
3D 프린팅 수정 / TFLite 변환 분석 / 전처리 과정 요약 및 결론
3D 프린팅 수정
기존에 모델링하였던 손목 디바이스의 경우 다음과 같이 스트랩이 짧은 세로 부분에 위치해 손목에 긴 가로 부분이 위치하게 되어 디바이스가 잠을 자면서 흔들리게 될 수 있다는 우려가 있었다.

따라서 스트랩이 위치할 고리 부분을 반대로 하여 디바이스가 이전보다 흔들리지 않게끔 조정하였고 세부 길이도 조절해 마찬가지로 스트랩의 고정에 안정성을 더했다.

PPG 시그널 전처리 서베이
지난주에 다음과같은 심박수 데이터를 전처리를 통해 정규화시키고 라벨링과 매핑시키는 것을 성공했었다.
전처리는 다음과 같은 과정을 통해 이루어졌으며, 해당 심박수 데이터를 추출하기 위해선 근본적으로 PPG 시그널에서의 전처리 작업 및 특징 추출이 굉장히 중요하다.
따라서 심박센서의 수령 전까지 PPG 시그널의 적절한 노이즈 필터링 및 전처리 작업에 대한 조사를 진행하고, 적용할 만한 방법들을 추려 적용 계획을 세워본다.
- 심박수 데이터 라벨링 데이터 시간 동기화
- 유효한 interval 찾고 unscored 된 심박수와 라벨링 잘라내기
- 잘라진 부분 선형 보간을 통해 보충하기
- cycle(30초) 내에서 대표가 되는 심박수 값 뽑아내기
- 가우시안 정규화와 표준편차를 취하기
PPG 시그널 및 전처리 필요성
광혈류측정 센서(PPG Sensor)는 혈관 조직의 혈액량 변화를 측정한다. 센서의 빛이 주변 조직을 조명하는 데 사용되며, 다양한 조직 층을 통과하면서 산란되고 흡수되며, 이때 감쇠된 센서의 빛 강도는 광학 센서에 의해 감지되어 PPG라고 하는 전압 신호로 기록되는 것이다.
이때 Raw PPG 시그널에는 일명 심박수(BPM)으로 불리는 각 심장 박동마다 발생하는 동맥 혈액량의 변화에 의한 고주파 AC Signal 이 존재하고, 이외에 위에서 언급한 다양한 조직층 구성 요소에 의한 광선의 감쇠 변화가 반영된 노이즈, 저주파 DC Signal 이 있다.
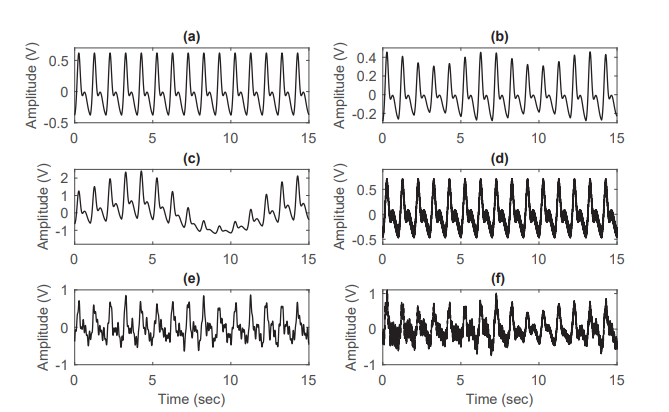
위와 같은 노이즈가 존재하기 때문에, PPG 신호 분석에는 여러 가지 어려움이 있어 PPG에서 신뢰할 수 있는 정보를 추출하는 것이 중요한 작업이다. 여러 생리학적 변화를 나타내는만큼, 그 중 일부인 심박수만을 추출하여 작업에 사용해야만한다.
필터링 방법(노이즈 제거)
영상처리에서도 사용되는 필터링도 PPG 시그널과 같은 시계열 데이터에 사용이 가능하다. 필터링은 LPF, HPF를 사용하여 저주파 및 고주파 노이즈와 같은 특정 주파수 범위 내의 노이즈를 감쇠하는 데 사용이 가능한데, 위에서 설명했던대로 PPG 시그널에서 우리가 타겟으로 설정한 심박수를 얻기 위해선 고주파 대역의 신호가 필요하다. 이를 위해 HPF를 사용하여 심장박동에 해당하는 신호를 추출해내고 후속 필터링으로 고주파 신호의 노이즈들을 제거하는 것이 적절한 시도라고 볼 수 있을 것이다.
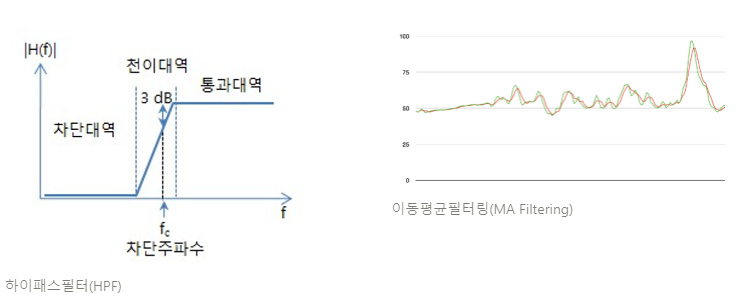
뿐만 아니라, 바이오의학 신호 처리 분야에서 가장 일반적으로 사용되는 필터링 기술로 이동 평균 필터링(Moving Average Filtering)이 존재한다. 이 필터는 미리 지정한 sliding window 크기의 샘플의 평균 값, 혹은 중앙값으로 해당 포인트값을 결정하는 필터링 방법이다. 해당 필터링 기술을 이용하여 HPF으로 추출된 고주파 PPG 시그널에 대하여 MA Filtering을 적용하여 최종적으로 고주파 시그널의 노이즈까지 필터링하는 것 또한 적합해보인다.
전처리 단계 추후 작업
- PPG 시그널의 적절한 전처리 방법을 서베이하였으며, 차주에 이를 적용할 수 있는 전처리 코드 완성 예정.
- 전처리 성능 비교를 위해 추후 손목 디바이스가 완성되어 스마트워치와의 성능비교 테스트를 수행할 때 두가지 경우(전처리 적용, 미적용)를 동시에 계산하여 성능의 변화를 요약해보겠음.
- 이외에도 Time Domain에서의 PPG 전처리 기법인
- Detection of maxima from the PPG
- Identification of maxima from the 2nd derivative of the PPG
- Detection of maximum upslopes using the first derivative
- Identification of pulse onsets using Wavelet transform
를 구체적으로 조사하며 적용가능성을 판단할 것임.
To do
- 지난 금요일 심박센서까지 배달이 완료되었다. 바로 실측을 측정하여 하드웨어 설계도를 수정하고, 3D 프린트 케이스 제작 및 모듈 납땜 실시 예정(과사 연락 완료)
- 모델이 완성되었다. 이를 tflite 언어의 모델로 바꾼후 flutter에 모델을 이식하여야한다. 또한 flutter에서 정확한 구동을 확인하여야한다.
- 우리가 완성한 모델은 우리가 만든 데이터셋이 아닌 받아온 데이터셋이므로 데이터 우리가 수면하면서 자체적으로 데이터셋과 같은 특징추출 및 전처리를 진행하여 모델에 추론을 맞출 수 있게 하여한다.
- 하지만 우리가 센서로부터 받아오는 값은 심박수가 아닌 pleth 데이터일 것이다. 따라서 우리는 해당 데이터를 지난 번에 완성했던 심박수 추출 과정을 통해 심박수로 바꿔줄 것이며 바꿔진 심박수 데이터를 전처리했던 과정과 마찬가지로 가우시안 정규화와 표준편차를 취해줘 학습했던 데이터와 동일한 형태로 추론(수면단계)을/를 얻어낼 것이다.