5월 2주차 Weekly Report
Table of contents
주간 작업 내용
5월 2주차 작업내용이다. 팀원별 업무 내용은 다음과 같다.
박종현 : 수면 심박수 측정, PPG 시그널 전처리 계획
이제욱 : 수면 단계 모델 학습 데이터 전처리, 수면자세 데이터 수집, 가속도 모델 학습 및 변환
이태우 : 수면단계 모델 성능평가 및 개선
-
05.07(화) 19:00~21:00 : 진행상황 공유 및 역할 분배
-
05.09(목) 22:00 ~ 04:00 : 발표 ppt 제작 및 준비
-
이외 시간 자택 작업 진행
수면단계 파트
수면 심박수 측정
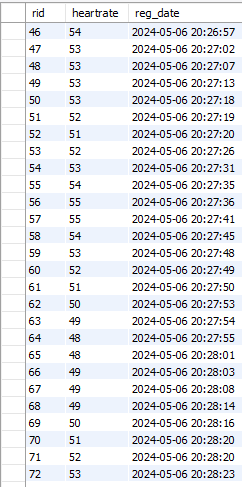
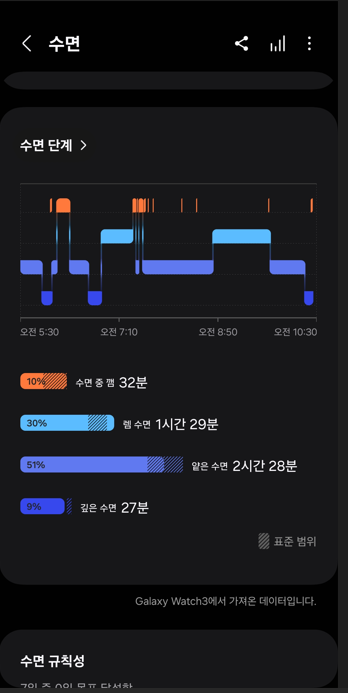
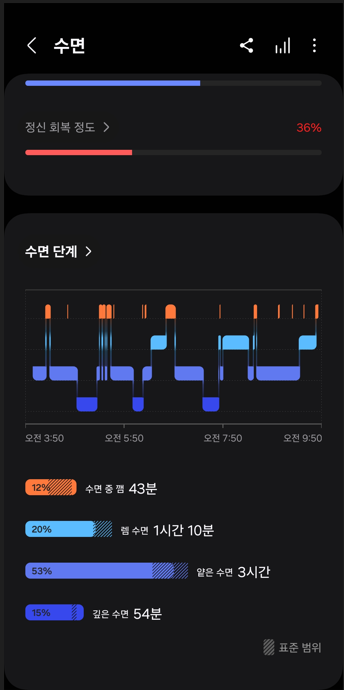
지난 한 주동안 데이터 저장 환경 세팅을 끝냈고, 미밴드와 갤럭시워치를 동시에 착용하여 심박수와 수면 정보를 수집하였다. 하지만 미밴드는 폐기되었기 때문에 처분해야한다. 시간을 낭비해서 다음 일정에 속도를 내야함.
PPG 시그널 전처리 계획
- 하드웨어 및 실험환경 제어
미밴드 사용 미허가로 다시 PPG 센서를 이용해야 함. 기존 PPG 센서 측정시 문제였던 것은 센서 피크의 명확한 구분이 어려웠던 것도 있지만, 측정 후 일정시간이 지나면 센서가 측정이 되지 않으며 일정한 값만 출력되는 상황이 발생했음. 해당 원인을 명확히 모르기에 월요일부터 샘플링 주파수를 변화시키거나 실험환경을 달리해서 올바르게 측정이 될 때까지 실험 진행 예정.
추가로, 신규 PPG 센서를 수입할 예정이다. 기존 DFROBOT사에서 제공하는 센서로, 원래 해외배송 제품이라 개발이 지연될 것으로 예상되어 구입하지 않았지만, 이번에 국내 재고가 채워지게 되면서 디바이스 마트 구매가 가능해졌음. 내일 해당 센서와 함께 납땜 물품들까지 한번에 구매요청 진행 예정.

- 소프트웨어 및 디지털 신호처리
하드웨어 실험외에도 신호 처리를 위한 여러 방안들을 찾아보고 있다. 센서 불확실성을 해결하기 위한 연구를 중심적으로 서베이하였다.
우선 Sensor Calibration의 경우, PPG 단독 파라미터에 선형 오프셋이 있을 경우 PPG 출력 전압의 스케일은 달라지더라도 피크가 생성되는 주기는 변하지 않기 때문에 심박수 추출을 위한 RR간격 추출에는 영향이 없음을 알수 있다(아래 그림, 출처 https://support.slatesafety.com/article/23-ppg-heart-rate-sensing-and-calibration).
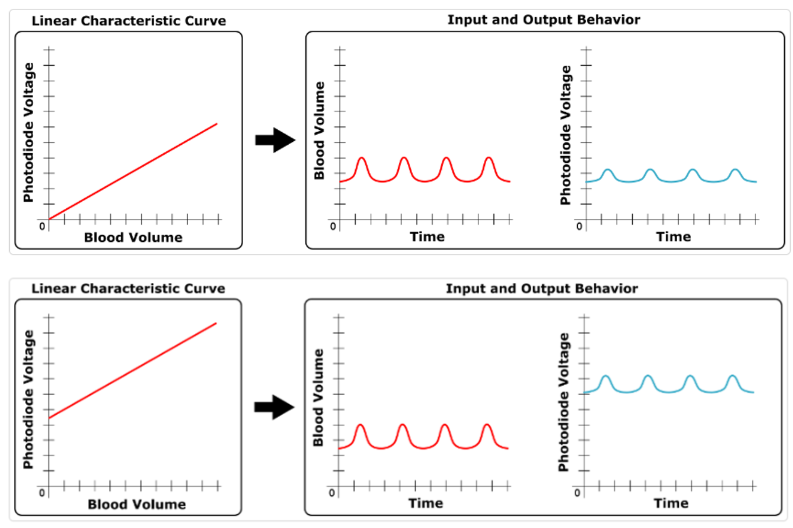
뿐만 아니라 가장 문제가 되는 비선형 특성+오프셋이 존재하는 경우, 기타 센서의 경우 켈리브레이션이 필수적이지만 마찬가지로 PPG 센서는 피크간의 거리는 일정하게 측정되기 때문에 켈리브레이션이 필요하지 않다(아래 그림).
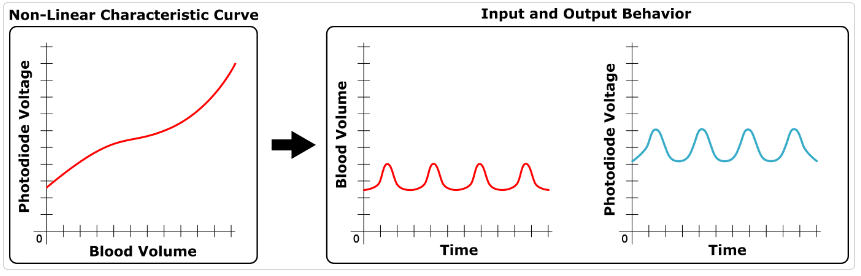
실제로 위와 같은 PPG의 장점을 이용하여, 혈압 측정 및 ABP 측정 목적의 심혈관 의료기기를 켈리브레이션하는데 PPG센서가 사용하는 연구가 다수 진행되고 있기에 (A PPG-Based Calibration-Free Cuffless Blood Pressure Estimation Method Using Cardiovascular Dynamics, Hamed Samimi), (Calibration of the photoplethysmogram to arterial blood pressure: capabilities and limitations for continuous pressure monitoring, P Shaltis) 소유한 PPG 센서의 켈리브레이션은 Min-max 스케일링 수준만 적용하더라도 심박추출에 문제가 없을 것으로 보인다.
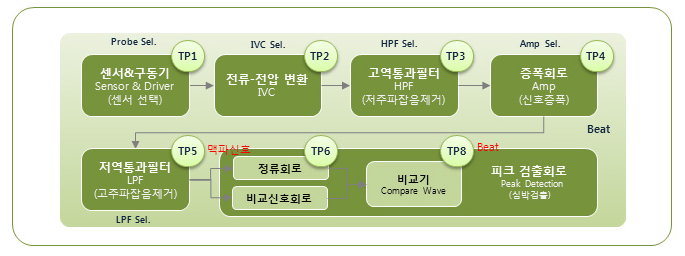
센서의 Raw Data 불확실성 제어를 위한 또 다른 방법으로, 기존에도 시도했던 디지털 신호처리 방법이 존재한다. 피지오랩에서 제공하는 15만원 상당의 PPG-심박 의료기기에서 수행되는 센서 Raw Data 필터링 작업은 아래 사진과 같으며, 기존에 시도했던 대로 HPF, LPF로 특정 주파수 대역(0.6~3.3Hz의 밴드패스필터링과는 다르게 여기서는 0.1Hz의 HPF와 10Hz의 LPF를 사용하였음. 출처 https://www.devicemart.co.kr/goods/view?no=1328963)을 통과시켜 노이즈를 제거하여 정제된 PPG 신호를 얻어내고, 이에 대해 피크 탐지 알고리즘을 수행한다.
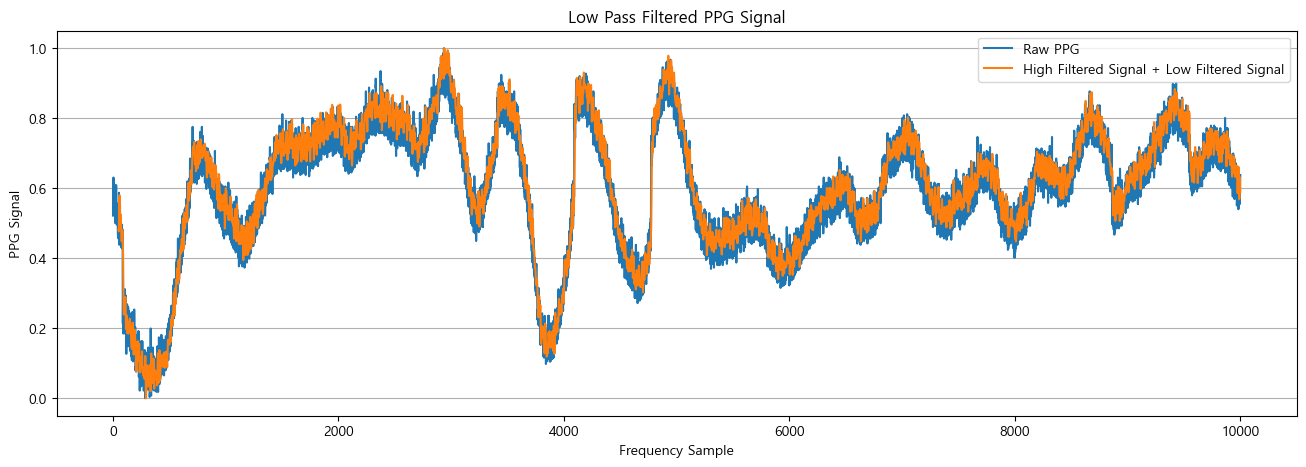
아래 그래프에서 좌측은 처음으로 구매했던 Crowtail PPG 센서의 손목 측정 데이터 중 가장 이상적으로 측정된 부분만 잘라내서 위의 필터링 결과를 도입한 결과이고, 우측은 기존에 적용했던 0.6~3.3Hz 밴드패스 필터링을 적용한 결과이다. 센서의 노이즈가 어느정도 제거된 것을 확인할 수 있으며, 노이즈 제거의 성능은 우측의 밴드패스필터링이 더 우수하여 이를 사용하는 것이 보다 적합해 보인다.
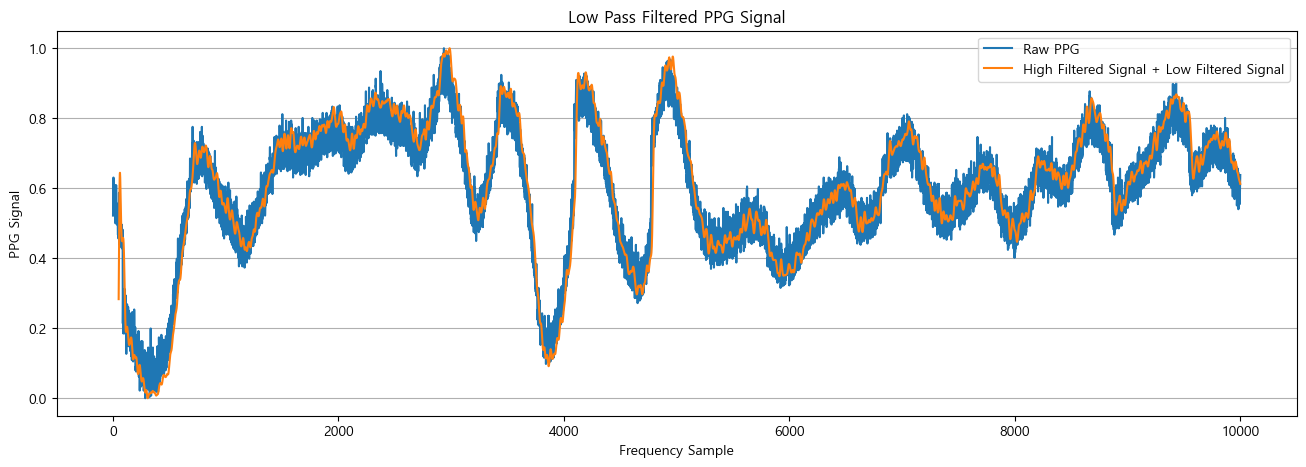
추가로, 여러 시도 중에 위의 주파수대역 필터링도 노이즈 제거 성능이 좋지만 아래처럼 단순이동평균 필터도 노이즈 제거에 적절한 성능을 보여주어 적용가능성이 충분해보인다.
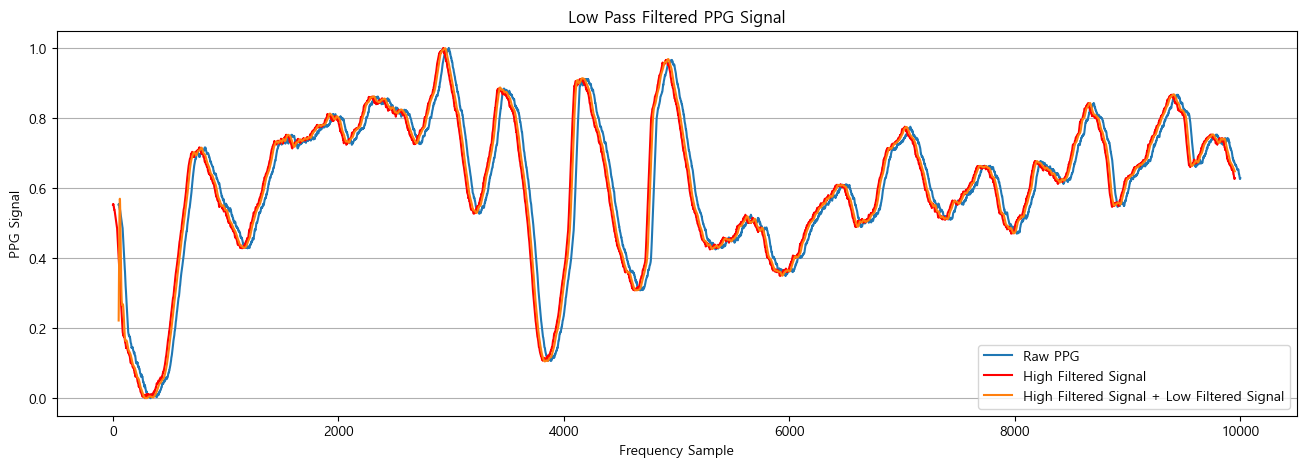
- 결론
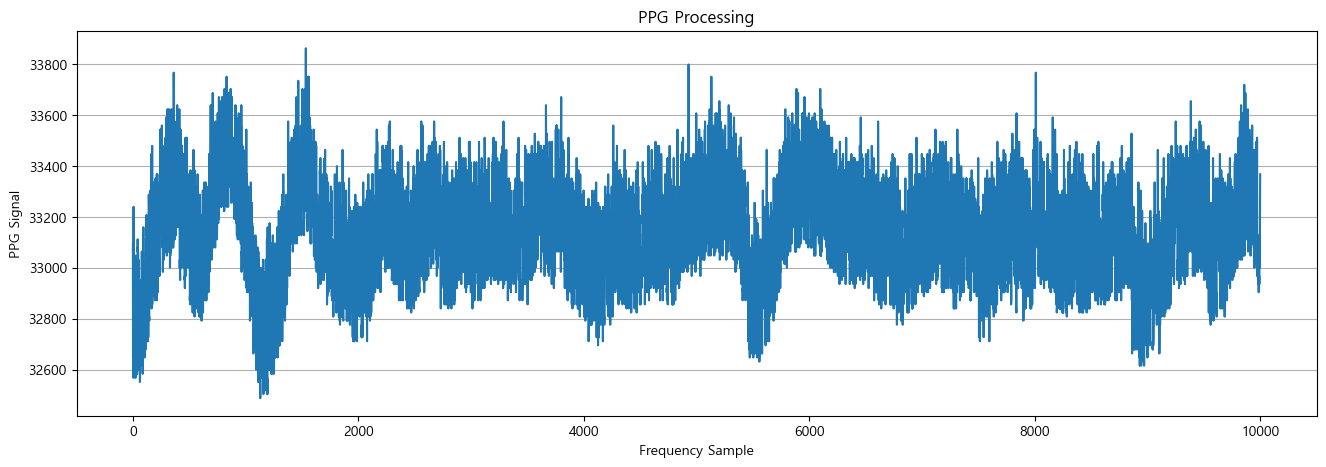
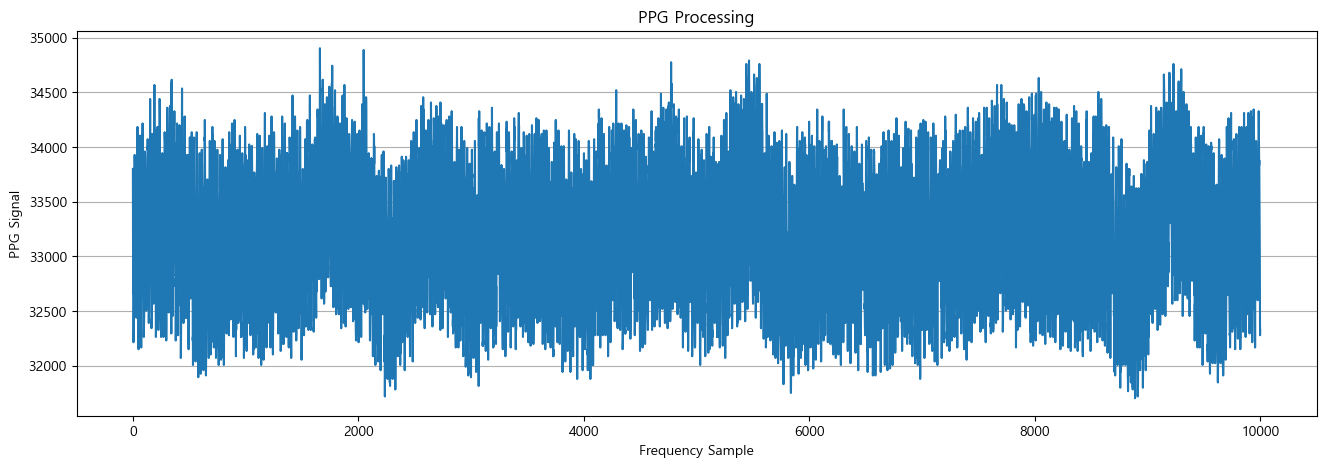
위와 같은 결과를 분석할 때, 디지털 신호처리는 확실히 효과가 존재하는 것으로 보인다. 하지만 가장 큰 문제는 항상 위처럼 측정되는 경우가 발생하지 않는다는 것이다. 아래 두 그래프를 보면, 특정 경우에는 파형의 진폭이 일정하게 유지되기도 하는 경우가 발생한다. 제적한 케이스에 부착한 상태로 측정했음에도 측정마다 다른 결과가 유지되는 이유는
- 케이스와의 접착면이 완전하게 붙지 않아 신체의 움직임에 PPG 센서가 흔들려 손목과의 거리가 멀어지는 경우
- 오히려 아래처럼 진폭이 줄어든 상황이 정상 시그널이고, 여기서 신호처리를 올바르게 해야하는 경우
로 보인다. 어찌됐든 PPG 센서를 반드시 사용해야하는 상황이고, 빠른 시일내에 이를 해결하지 못하면 안되니 월요일부터 종일 실험환경 통제와 함께 신호처리에 몰두할 것이다..
수면 자세 파트
수면 단계 모델 학습 데이터 전처리
- 심박수 매핑
수면 단계 모델을 학습할 떄 수면 단계 라벨과 실제 심박수의 타임스탬프가 맞지 않는 즉 매핑이 되지 않는 문제가 있어서 전처리하는 과정을 거쳤고 방법은 크게 3가지로 하였다.
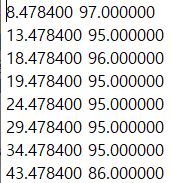
라벨링의 타임스탬프는 30초의 등차수열로 인터벌은 0 ~ 30 ~ 60과 같이 반복된다.
아래의 사진을 보면 매핑이 되지 않는 것을 확인할 수 있다.

- 평균값
알고리즘은 다음과 같다.
인터벌 사이에 존재하는 모든 심박수 데이터들을 더해 나눠 평균으로 매핑한다.
first_index = 0
for i in range(0,len(label)-1) :
head = first_index
# unscored 거르기
if label[i] == -1 :
while label_time[i+1] > hr_time[head] :
head = head + 1
if head >= len(hr_time) :
break
first_index = head
if head >= len(hr_time) :
break
continue
cnt = 0
sum = 0
while label_time[i+1] > hr_time[head] :
head = head + 1
if head >= len(hr_time) :
break
sum = sum + hr[head]
cnt = cnt + 1
if cnt == 0 :
continue
cropped_seconds_list.append(label_time[i])
cropped_label_list.append(label[i])
cropped_heart_list.append(int(sum/cnt))
first_index = head
if head >= len(hr_time) :
break
- 가장 가까운 값
알고리즘은 다음과 같다.
인터벌 사이에 존재하는 심박수 데이터들 중 라벨링 타임스탬프에 가장 가까운 값으로 매핑한다.
first_index = 0
for i in range(0,len(label)-1) :
head = first_index
# unscored 거르기
if label[i] == -1 :
while label_time[i+1] > hr_time[head] :
head = head + 1
if head >= len(hr_time) :
break
first_index = head
if head >= len(hr_time) :
break
continue
cnt = 0
while label_time[i+1] > hr_time[head] :
head = head + 1
if head >= len(hr_time) :
break
cnt = cnt + 1
if cnt == 0 :
continue
cropped_seconds_list.append(label_time[i])
cropped_label_list.append(label[i])
cropped_heart_list.append(hr[head-cnt])
first_index = head
if head >= len(hr_time) :
break
- 선형 보간
알고리즘은 다음과 같다.
라벨링 타임스탬프를 기준으로 양 옆 가장 가까운 값을 찾은 뒤 거리에 따른 가중치를 부여한 뒤 심박을 매핑한다.
first_index = 0
for i in range(0,len(label)-1) :
head = first_index
# unscored 거르기
if label[i] == -1 :
while label_time[i+1] > hr_time[head] :
head = head + 1
if head >= len(hr_time) :
break
first_index = head
if head >= len(hr_time) :
break
continue
cnt = 0
first_value = 0
if head == 0 :
first_value = 0
else :
first_value = hr[head-1]
while label_time[i+1] > hr_time[head] :
head = head + 1
if head >= len(hr_time) :
break
cnt = cnt + 1
if cnt == 0 :
continue
cropped_seconds_list.append(label_time[i])
cropped_label_list.append(label[i])
interpolated_hr = hr[head-cnt] * ( hr[head-cnt] / (hr[head-cnt] + first_value)) + first_value * ( first_value / (hr[head-cnt] + first_value))
cropped_heart_list.append(round(interpolated_hr))
first_index = head
if head >= len(hr_time) :
break
위와 같이 매핑된 심박수로만 모델 학습을 진행했을 때 학습이 잘 되지않는 것을 확인했고 추가적인 특성을 추출하여 학습에 사용하였다.
- 수면시간 특성
특정한 시간대에 특정한 수면단계를 가지고 있음을 전제하에 사용하였다. 라벨링 타임 스탬프를 의미하며 모든 시간에 대해 처음 기록 시간을 빼 정규화를 시켰다.
- 주기성 특성
시계열 데이터 특성 상, 수면단계도 일정한 사이클을 가지고 반복되기 때문에 도입하였다. 수면 시간을 라디안 단위로 변환하고 코사인 함수를 통해 주기적 특성을 뽑아낸다.
주기성 추출에 사용된 코드는 다음과 같다.
def cosine_proxy(time):
sleep_drive_cosine_shift = 5
return -1 * np.math.cos((time - sleep_drive_cosine_shift * 3600) * 2 * np.math.pi / (3600 * 24))
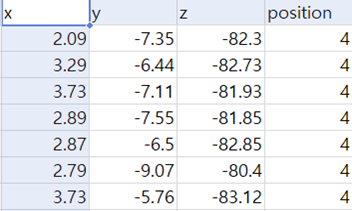
최종적으로 학습에 사용된 데이터셋은 다음과 같다.
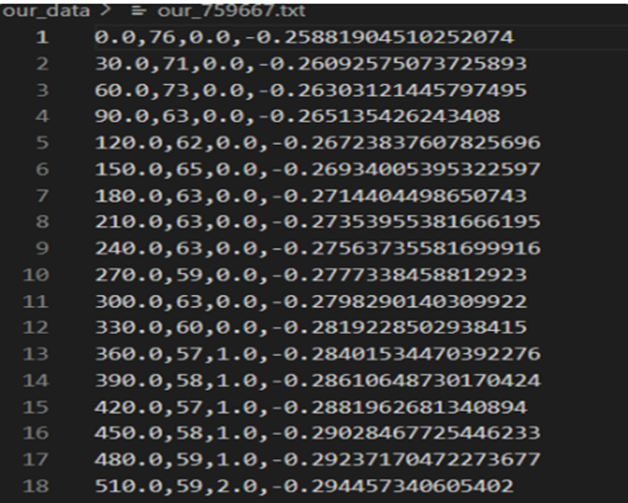
좌측부터 수면시간, 심박수, 라벨링, 주기성특성이다.
가속도 센서를 이용한 수면자세 데이터 수집
가속도 센서로부터 얻어오는 시그널을 이용하여 각도로 변환한 뒤 3개의 클래스로 수면 자세 모델 학습에 사용할 데이터를 수집하였다.
실제로 흉골에 센서를 위치하여 데이터를 수집하였으며 각 클래스당 1000개씩 총 4000개의 데이터를 수집하였다.
다음 사진들은 클래스와 실제 클래스별 데이터 형태이다.
- 클래스 1 (정자세)

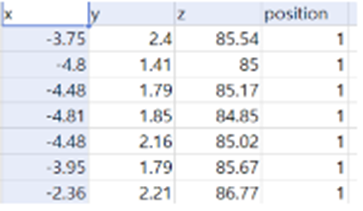
- 클래스 2 (왼쪽을 보며 누운 자세)

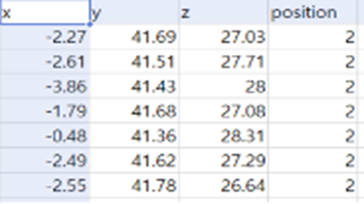
- 클래스 3 (오른쪽을 보며 누운 자세)

- 클래스 4 (엎드려 누운 자세)

가속도 모델 학습
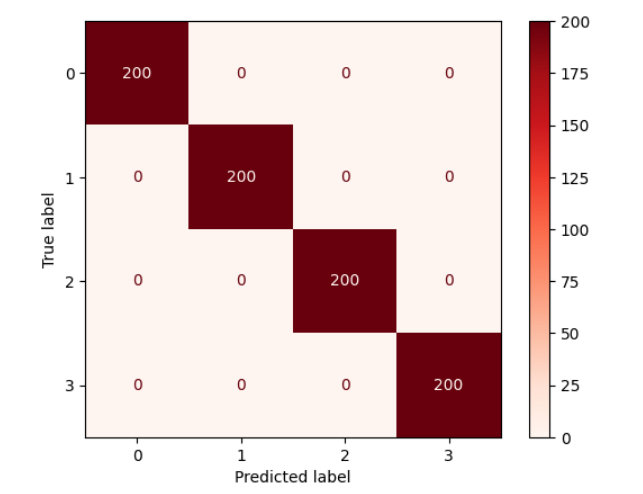
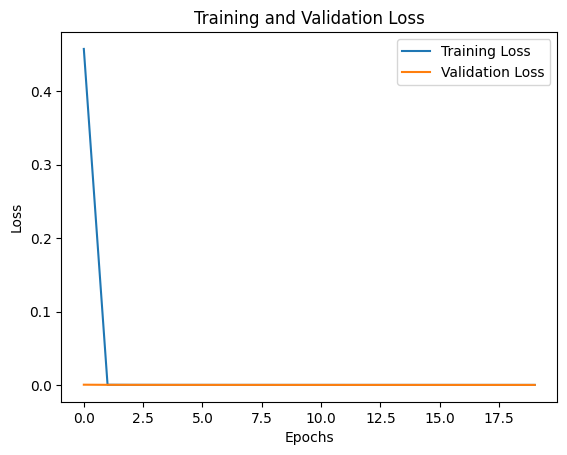
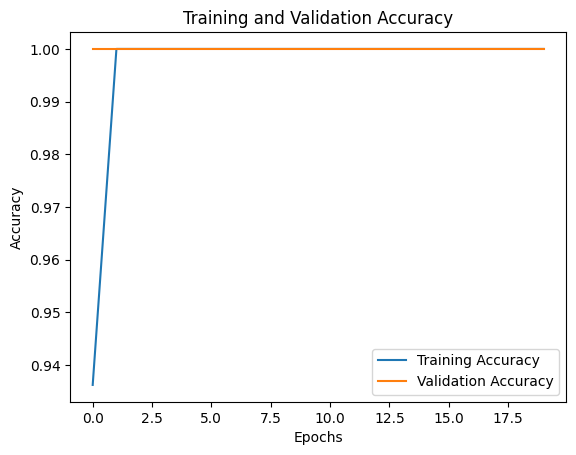
4000개의 데이터 중 800개를 Test로 3200개를 Train으로 나눈뒤 학습했을 때의 결과이다.
모든 경우에 대해서 완벽하게 수면자세를 판별하는 것을 확인할 수 있다.
학습된 가속도 모델 TFLite 변환
다음과 같은 코드로 TFLite 변환에 성공하였으며 테스트하였을 때 정상 작동하는 것을 확인할 수 있었다.
import tensorflow as tf
# Load the Keras model from the H5 file
keras_model = tf.keras.models.load_model('sleep_position_model.h5')
# Convert the Keras model to a TFLite model
converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
tflite_model = converter.convert()
# Save the TFLite model to a file
with open('sleep_position_model.tflite', 'wb') as f:
f.write(tflite_model)
수면단계 모델 개발 파트
앞서 데이터에서 심박수와 수면단계 라벨링값이 서로 일치하지 않는 문제가 존재하였다. 이는 심박수의 시간 단위와 수면단계의 라벨링 값의 단위 시간이 서로 다른 것이 원인 이였다. 두 값을 맵핑 해주기 위하여 심박수의 주기와 수면단계 라벨링 값을 맞춰줄 필요가 있었다. 이를 해결하기 위한 방식이 총 3가지가 있었다.
- mean
- interpolate
- greedy
먼저 mean을 기준으로 데이터를 nomalize후 accuracy를 확인해보았다. nomalize는 min-max nomalize를 이용하여 nomalize를 진행하였다. 이때 min-max nomalize를 사용하는 이유는 실제로 측정할 때는 값을 한꺼번에 여러개 입력이 불가능 하기 때문에 평균을 구하기 힘들기 때문이다. 즉 local min-max를 이용한다. 코드의 동작은 데이터를 입력받는 순간 nomalize를 해준다. 아래는 다음과 같은 코드이다.
def load_feature_data(base_path, feature_pattern):
all_data = []
for filename in os.listdir(base_path):
if feature_pattern in filename:
file_path = os.path.join(base_path, filename)
try:
data = pd.read_csv(file_path)
print(f"Loaded {file_path} with shape {data.shape}") # 각 파일의 형태 출력
if data.shape[1] > 1:
first_col = data.iloc[:, 0] # 첫 번째 열 선택
second_col = data.iloc[:, 1] # 두 번째 열 선택
normalized_col1 = (first_col - first_col.min()) / (first_col.max() - first_col.min())
data.iloc[:, 0] = normalized_col1 # 정규화된 열로 대체
normalized_col2 = (second_col - second_col.min()) / (second_col.max() - second_col.min())
data.iloc[:, 1] = normalized_col2 # 정규화된 열로 대체
all_data.append(data.values) # 데이터를 numpy 배열로 변환
except Exception as e:
print(f"Error reading {file_path}: {e}")
if all_data:
try:
return np.concatenate(all_data, axis=0)
except ValueError as e:
print(f"Error concatenating data: {e}")
# 오류 발생시 각 데이터의 차원을 출력하여 문제를 진단
for i, arr in enumerate(all_data):
print(f"Array {i} shape: {arr.shape}")
raise
return np.array([]) # 데이터가 없으면 빈 배열 반환
이제 이 nomalize를 한 데이터들을 모델에 올려서 학습을 진행할 것이다. input은 심박수 데이터이고 output은 [wake,n1,n2,n3,_,rem] 이 6개의 class를 분류하는 것이다.
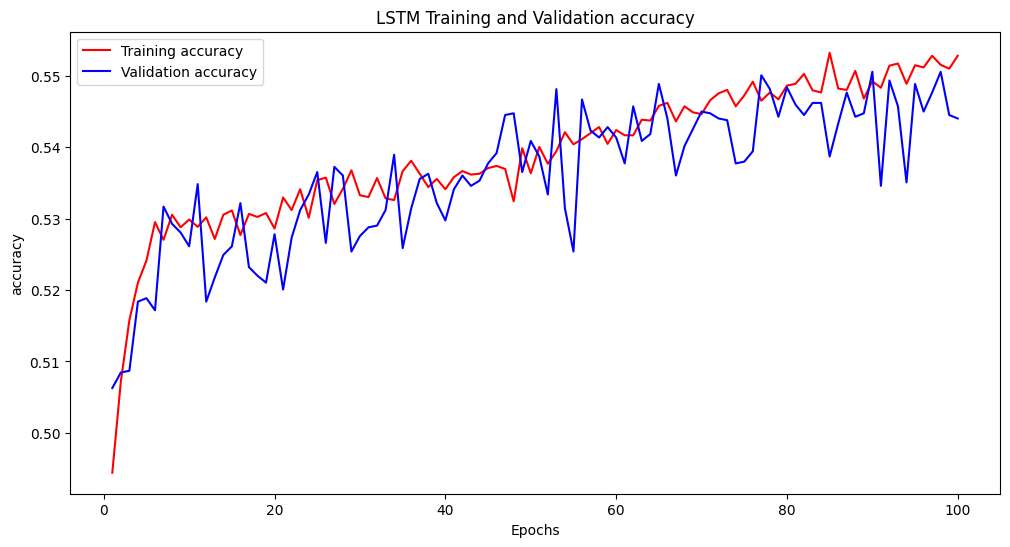
모델을 돌려 본 결과 학습이 제대로 이루어 지지 않은 모습을 확인 할 수 있다. 이는 심박수 데이터 값 하나만으로는 수면단계를 판단하기 힘들다는 결론에 도달하였다. 다른 특징을 추가할 필요가 있었다. 그래서 수면시간 특성을 추가해 보았다.
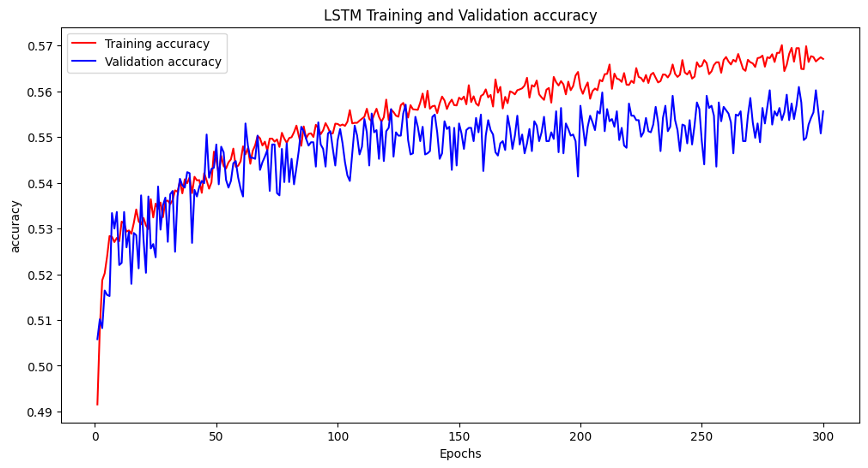
수면시간 특성을 추가한 결과 학습이 진행되긴 하였으나 여전히 accurcy가 낮은 현상이 존재하였다. 이에 주기성 특징을 추가하여 총 3가지 입력을 넣어보기로 하였다.
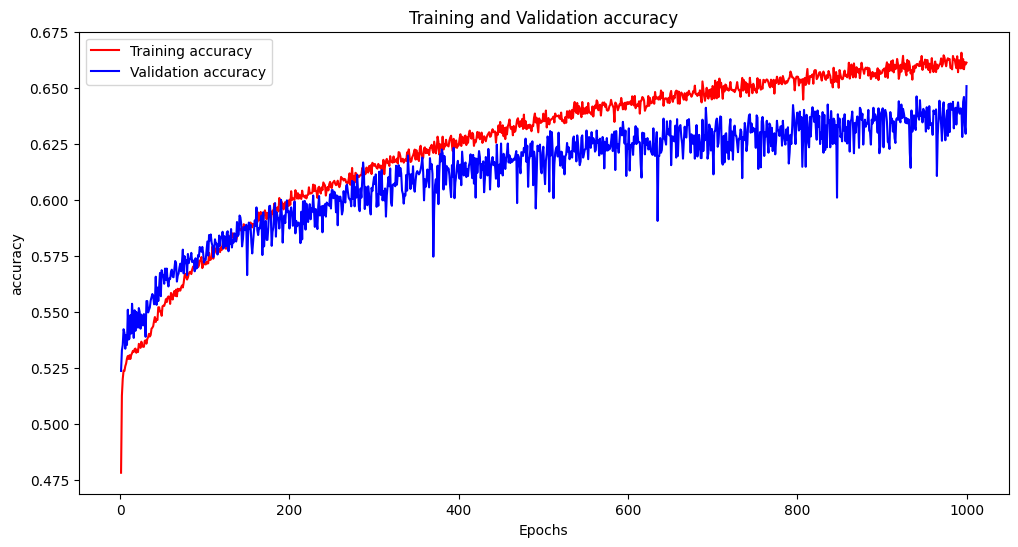
주기성 특징을 하나 더 추가한 결과 기존 accuracy가 55%에서 65%로 향상되었다. 여기서 기존 제품들은 [깸,얕은 수면, 깊은 수면, rem] 이 4클래스로 분류를 하기 때문에 기존 제품의 클래스 대로 클래스를 4개 Class=[wake, light_sleep, deep_sleep, rem]로 축약할 필요가 있었다.
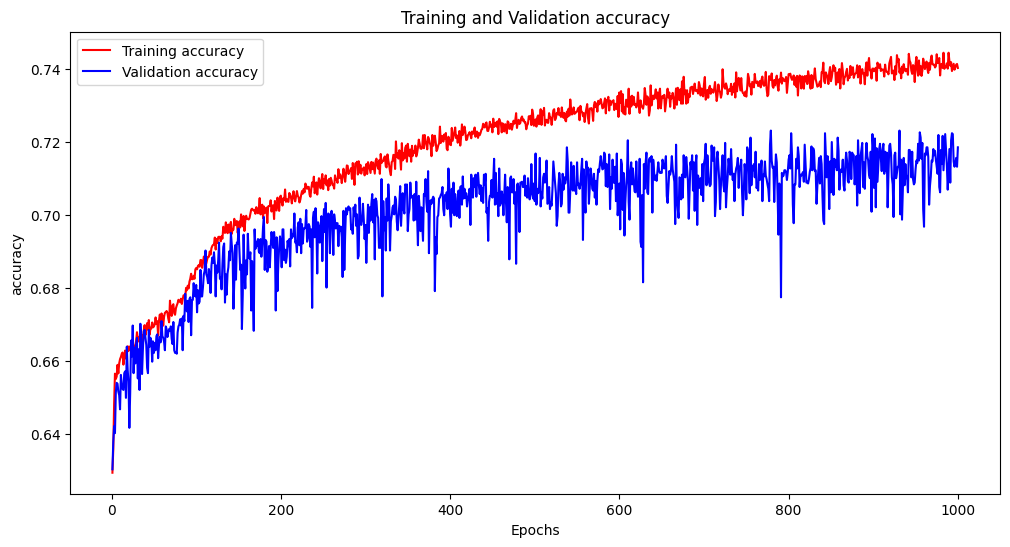
클래스를 4개로 축약한 결과 accuracy가 72%로 향상되었다. 여기서 우리는 클래스를 3개로 더 축약할 필요가 있었는데 모델에서 판별후 진동을 제어하기 위함이었다. 클래스 3개는 다음과 같다. 여기서 클래스를 2개가 아닌 3개로 분리한 이유는 _값을 사용하지 않기 위함이다. 4값에 해당되는 값은 필요가 없는 값이기 때문에 binery classification을 한다면 _값인 noise가 함께 들어가서 값이 부정확해진다.
- _ → 0
- 비작동 구간 (WAKE, REM, N1) →1
- 작동 구간 (N2, N3) →2
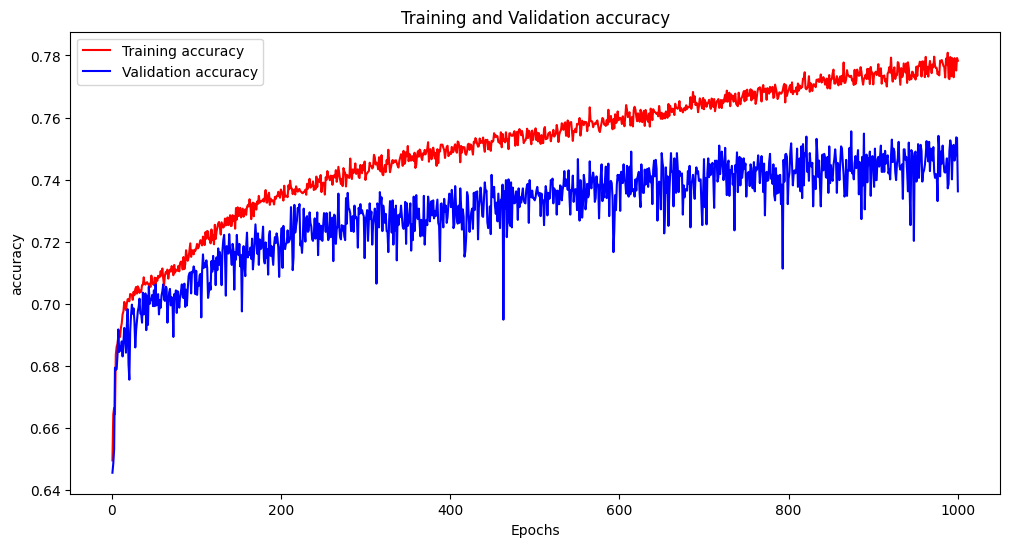
클래스를 3개로 축약한 결과 accuracy가 76%의 값을 보였다. 이제 이 값과 interpolate, greedy mapping 값과 한번 비교를 해보자.
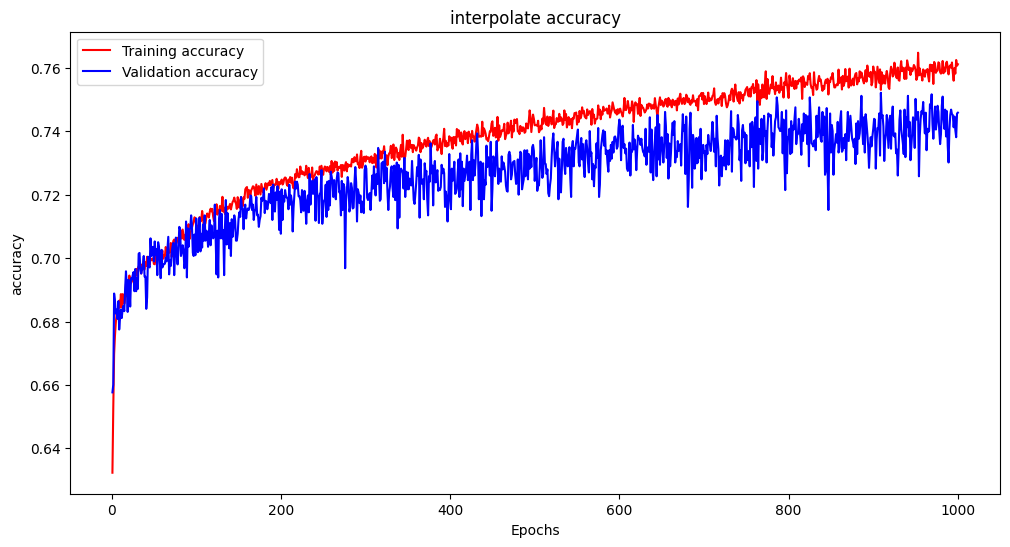
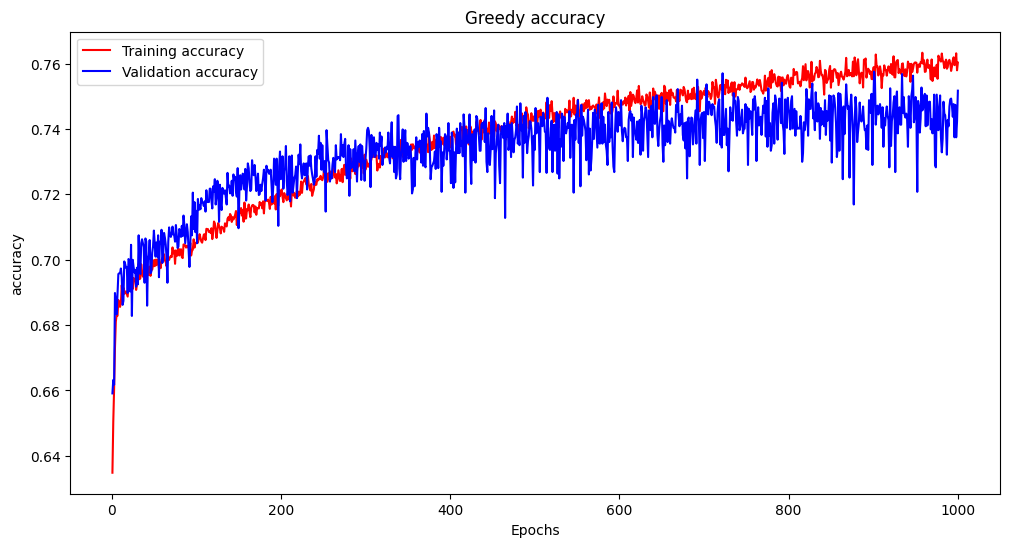
- mean → 76.6%
- interpolate 74.7%
- greedy 73.5%
Todo
| Name | Work Content |
|---|---|
박종현 | PPG 센서 연구와 신호 처리에 집중할 것 |
이제욱 | 피코 플러터 블루투스 통신으로 가속도 센서에서 추출한 각도가 정상적으로 도달하는지 확인하고 모델까지 실어 수면 자세 판별 가능한지 확인할 것 |
이태우 | 실제 측정 데이터로 수면 단계 모델 학습 진행 그리고 수면 이상치 모델 개발 시작할 것 |